새 페이지 1
엔터프라이즈 데이터를 완벽하게
활용하기 위한 도전
조직이 커지고 데이터가 증가하게 되면서, 그 데이터를 저장하고 분석하고 활용을 하기
위한 애드혹(ad hoc)시스템이 나타나기 시작했습니다. 중복된 데이터 인프라, 다중의 스토리지 시스템, 풀타임 관리 노력,
그리고 데이터 수정 작업들은 기업에게 평균 200%의 데이터 관리비용을 추가합니다.
|
 |
데이터 관리 전문가는 다음 세 가지 도전에 직면하고 있습니다
- 다중의 데이터 캡처와 스토리지 환경의 중복 및 관련 위험 제거
- 조직 전체에서의 데이터 품질 및 재사용성 극대화
- 모든 사용자들에게 명확하고 효율적인 데이터 커뮤니케이션
조직을
통틀어 필수 데이터의 정교한 해석과 재사용은 의사결정의 속도를 빠르게 할 수 있습니다.
복잡한 데이터 구조의 존재 인식은 몇몇 기업들만 갖고 있으며, 점점 더 악화되는 상황을
개선시키는 인지 비용에 부담을 갖게 됩니다.
ER/Studio Data Architect는 문서화와 기존의 데이터베이스를 개선하는 기능들은 데이터의 일관성을 향상시키고 전사에 걸친
모델을 효과적으로 커뮤니케이션 할 수 있도록 합니다.
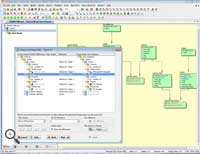 |
ER/Studio Data Architect는 사용하기 쉬운 시각적인 인터페이스를
제공하여 기존 DB에 대한 문서화, 이해, 정보 배포가 매우 쉬우며, 그에 따라 비즈니스 목표 지원을 더 원활하게 할
수 있다. 업계를 리딩하는 데이터베이스 시스템에 대한 막강한 리버스 엔지니어링은 데이터 모델러가 쓸데 없는 중복 작업 없이 데이터
구조를 비교하고 통합 할 수 있게 해줍니다. |
또한, 모바일 데이터베이스와의 더 단단한 통합으로 ER/Studio Data Arhitect를
통해 데이터 모델러들은 모바일 애플리케이션에서 사용되는 데이터베이스들을 리버스엔지니어링 할 수 있으며, 성능을 최적화하고 문서화 할 수도
있습니다.
ER/Studio Data Architect는 모델과 복잡한 비즈니스 규칙을 명확하게 해줍니다. 멀티레벨 설계 레이어는 데이터를 정밀하게
시각화해주어 업무담당자와 기술담당자 사이의 커뮤니케이션을 촉진합니다.
주요 기능
- ER/Studio Data Architect의 내장된 기능들을 활용해 루틴한 모델링 작업을 자동화 할 수 있습니다. 이를 통해 데이터
모델러와 아키텍트들은 데이터베이스와 데이터 웨어하우스 설계를 이전보다 더욱 빠르게 최적화하고 분석할 수 있습니다.
- 기존의 데이터베이스를 개선하고 문서화할 수 있습니다.
- 데이터 일관성을 유지할 수 있습니다.
- 전사에 걸친 효율적인 모델 커뮤니케이션이 가능합니다.
- 데이터 통합과 정확성을 향상시키는 데이터 출처와 소재 추적이 가능합니다.
ER/Studio Data Architect
기능명세
ER/Studio에는 단독 제품은 Data Architect 에디션과 Enterprise 에디션(비즈니스 프로세스 모델링, 크로스 관리 협업,
글로벌 용어집 등 포함)이 있습니다. 아래의 표를 통해 각 에디션들이 제공하는 기능들을 확인할 수 있습니다.
| |
Data Architect Professional |
Data Architect |
Developer edition* |
| 물리 / 논리 모델링 |
|
|
|
| 포워드 / 리버스 엔지니어링 |
|
|
|
| 모델 리파지토리 클라이언트 (버전 컨트롤) |
|
|
|
| 메타데이타 임포트/익스포트 기능 |
|
|
|
| 모델 임포트 기능 포함 |
|
|
|
| HTML & RTF 리포트 생성 |
|
|
|
| 다양한 포맷의 리포트 생성(XML Schema, PNG, JPEG, DTD Output) |
|
|
|
| RDBMS 플랫폼 |
|
|
|
| 빅데이터 플랫폼 – MongoDB, Hadoop Hive |
|
|
|
| 데이터 소스 레지스트리 |
|
|
|
|
모델 기반 설계 환경의 높은 생산성 |
| 향상된 그래픽과 레이아웃 |
가독성과 검색기능이 강화된 하나 또는 결합된 레이아웃의 다이어그램 자동 생성 |
| 자동화 및 커스텀 변환(transformation) |
S논리설계로부터 하나 또는 다수의 물리설계를 생성 간소화하고 타겟 데이터베이스에 맞는 정규화 및 규정준수 체크 |
| 확장성 있는 자동화 인터페이스 |
반복 작업 자동화(테이블 색상표시, 표준용어 적용, 스토리지 파라미터 일괄변경, 데스크탑 응용프로그램과 통합) |
| 다양한 표현 방식 |
작업된 모델과 리포트는 HTML, RTF, XML 스키마, PNG, JPEG, DTD로 출력 |
|
완벽한 데이터베이스 라이프사이클 지원 |
| 포워드/리버스 엔지니어링 |
데이터베이스 설계로부터 소스 코드 생성. 기존의 데이터베이스 또는 스키마로부터 시각적인 데이터 모델 생성. 정형화된
변경(alter)코드를 이용하여 설계 변경 적용 |
|
엔터프라이즈 모델 관리 |
| 유니버설 맵핑 (Universal Mappings) |
개념, 논리, 물리 모델 간 상호 관계를 볼 수 있는 맵핑 |
| 향상된 비교&머지 |
모델과 데이터베이스 구조에 대한 향상된 양방향 비교 및 병합 |
| 팀 서버 통합 |
모든 데이터 소스를 중앙에서 동기화하며, 모델과 메타데이터에 대한 피드백 확인 가능 |
| 서브모델 관리 |
서브모델을 중첩하여 멀티레벨로 생성, 기존 모델 간 서브모델 병합, 계층 구조 동기화 기능 |
| 메타데이터 통합 |
다양한 소스(BI 플랫폼, UML, 데이터모델링 솔루션, XML 스키마, CWM-Common Warehouse
Metamodel)에서 메타데이터 임포트, 익스포트로 메타데이터 허브(hub) 생성 |
| 표준 데이터 사전 |
표준 데이터 요소, 네이밍 표준, 참조값 정의 및 시행 |
| "Where Used" 분석 |
논리 설계(엔티티, 속성)와 이것들로부터 구현된 여러 물리설계에 대한 맵핑 정보를 표시 |
| XML 스키마 생성 |
SOA(Service Oriented Architecture) XML 프로젝트들이 당신의 데이터모델과 같은 표준 기반에
있도록 보장 |
|
데이터웨어하우스 및 통합 지원 |
| 비주얼데이터리니지(Visual Data Lineage) |
시스템간 데이터 이동에 대한 맵핑 룰을 소스/ 타겟에 대한 연결을 통하여 시각적으로 문서화 |
| 다차원 모델링(Dimensional Modeling) |
스타(star) 스키마와 스노우플레이크(snowflake) 스키마 설계를 활용. 다양한 BI 또는 데이터웨어하우스
플랫폼으로부터 다차원 메타데이터 표현 |
|
데이터베이스 설계 품질 |
| 모델 유효성 검사 |
모델 검토를 자동화하고 오브젝트 정의 누락, 사용하지 않는 도메인, 동일한 인덱스, 순환참조 등 표준 체크 |
| FK(foreign key) 마이그레이션 자동화 |
설계의 참조 무결성 보장을 위해 FK(foreign key) 유지 |
|
보안 설계 및 평가 |
| 데이터 분류 |
개인정보보호 레벨에 따라 해당 정보에 부합하는 데이터와 오브젝트의 등급을 라벨링 및 카테고리화 |
| 권한 관리t |
논리와 물리 레벨에서 사용자, 역할, 그룹별 권한 관리 |
* RAD스튜디오 아키텍트 에디션에 포함되어 있는 ER/Studio Data Architect
Developer 에디션은 다음의 데이터베이스 플랫폼만 지원합니다:
Oracle
SQL Server
DB2 LUW
Interbase
MySQL
Informix
Sybase ASA
Sybase ASE
ODBC / ANSI SQL